

From Prototype to Production: How I Built a Multi-Agent AI System That Actually Works Across Platforms
Building an AI chatbot is easy today.
But building something that:
works reliably in production
maintains context across conversations
and runs across multiple platforms
…that’s where things start to break.
I ran into this exact problem while moving from a simple RAG-based setup to something more scalable. What started as a prototype quickly became hard to manage—context handling was inconsistent, routing logic became messy, and extending it to new platforms felt like rewriting the system.
That’s when I shifted to a multi-agent architecture using Google ADK.
The Problem with “Single-Agent” Systems
Most AI systems today follow a simple flow:
User input → Retrieval → LLM → Response
This works well initially. But as soon as you add:
multiple use cases
different types of queries
platform-specific interactions
…the system becomes difficult to scale.
One agent trying to do everything becomes the bottleneck.
The Shift: From One Agent to Many
Instead of building one “smart” agent, I moved to a system of specialized agents.
Each agent:
handles a specific responsibility
has its own tools and instructions
operates independently
At the center is a root orchestrator that decides which agent should handle a query.
This small shift changes everything.
How the System Works
Query Understanding
The system interprets the user’s intent along with context.Intelligent Routing
The orchestrator selects the most relevant agent.Execution
The selected agent:retrieves data
calls tools
or performs reasoning
Response Generation
The final response is generated using:retrieved knowledge
session memory
prior context
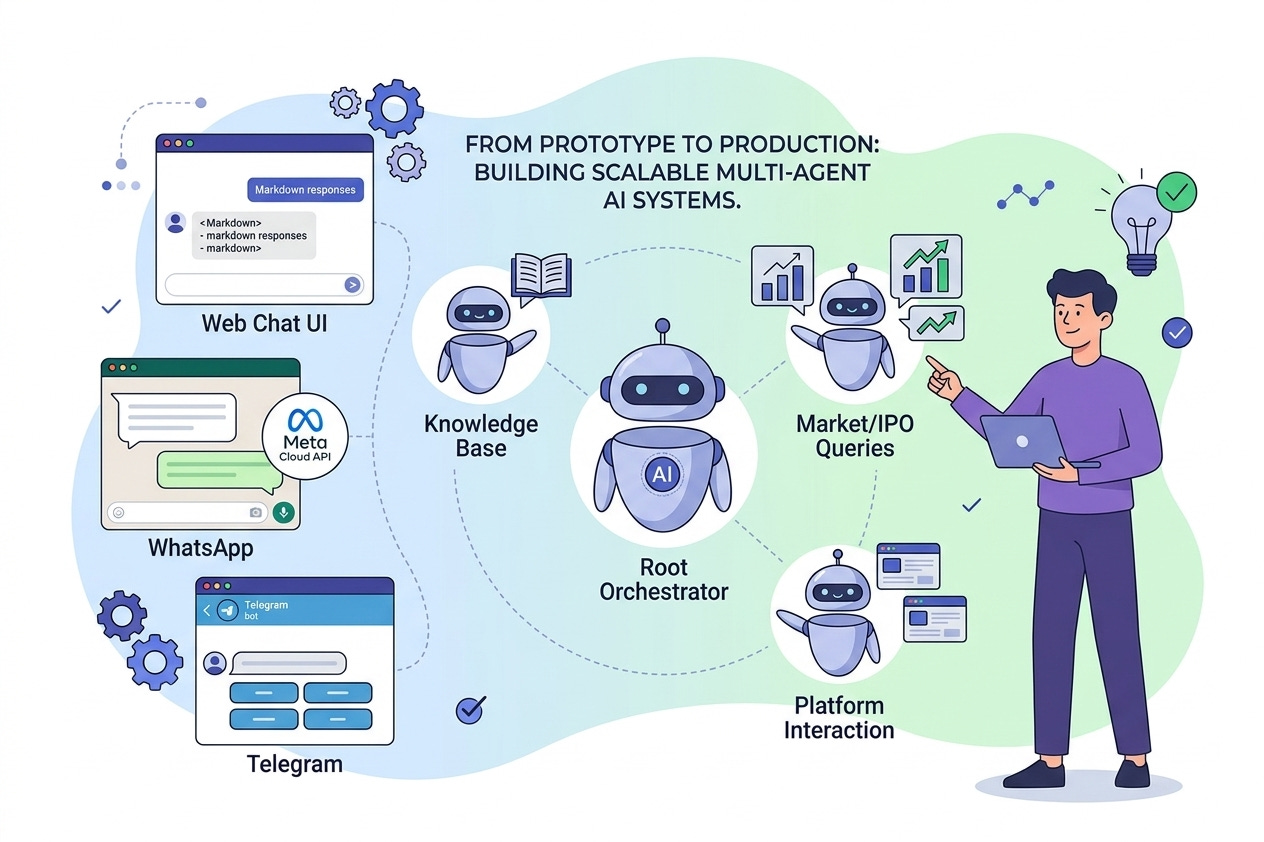
The Architecture I Built
I implemented this using a hub-and-spoke model:
Root Orchestrator
Doesn’t answer questions
Routes queries
Maintains context
Specialist Agents
Market-related queries
IPO-related queries
Knowledge base queries
Modular Composition
Agents are plugged in like components, making the system:
easy to extend
easy to debug
easy to scale
The Key Breakthrough: One Backend, Multiple Interfaces
One of the biggest improvements came from decoupling the AI system from the interface.
Instead of building separate logic for each platform, I used the same backend and connected it to multiple interfaces:
Web Interface (via LibreChat)
Full chat UI
Markdown responses
Session-based conversations
WhatsApp Integration
Connected using Meta Cloud API
Persistent memory using Redis
Works like a real assistant in chat
Telegram Bot
Lightweight interface
Interactive elements (buttons, quick actions)
Why this matters
All three platforms use the same underlying AI system:
same agents
same memory
same logic
Only the interface changes.
This means:
no duplication of logic
consistent responses everywhere
faster iteration and deployment
What Actually Improved
Moving to this architecture solved several real issues:
Context is maintained across conversations
Follow-up questions work naturally
Adding new features doesn’t break existing ones
Supporting a new platform doesn’t require rebuilding the system
A simple example:
“What is its P/E ratio?”
The system understands what “its” refers to—even across platforms.
What Makes This Work in Production
A few things made a big difference:
Orchestration layer → clean routing decisions
State management → shared memory across agents
Observability → ability to debug flows
Modular design → independent agents
Instead of stitching components together, the system behaves like a coordinated network.
The Bigger Shift
This experience changed how I think about AI systems.
It’s no longer about:
building a chatbot
It’s about:
designing a system of agents that can collaborate
Final Thought
Most AI systems fail not because of the model—but because of the architecture.
Moving from a single-agent setup to a multi-agent, multi-interface system made the difference between something that works and something that scales.
And the most important realization: Your AI shouldn’t live inside an interface.
The interface should connect to your AI.