

The Self-Improving Agent Platform
Skill Reuse, Self-Repair, and Shared Registries — How to Make Enterprise AI Compound Rather Than Decay
A Wohlig Transformations Whitepaper
Executive Summary
Enterprises that have shipped multiple AI agents into production are now confronting two structural problems. Token spend climbs monotonically because every invocation re-derives the same reasoning. Reliability decays silently because agents break when underlying tools and APIs change, with no automatic remediation loop.
The architectural fix is a Self-Improving Agent Platform — a middleware layer that captures successful workflows as reusable, versioned skills; auto-repairs them when they break; and distributes them across the organization through a governed registry. Industry data on this pattern shows ~46% token reduction and ~4.2x output value per agent invocation.
Wohlig builds this platform for enterprises in BFSI, professional services, BPO/KPO, and document-heavy operations. This paper describes the architecture, the governance model, the integration approach, and the engagement plan.
1. The Two Problems
1.1 Agent Decay
Agents built on raw LLM-plus-tool-call loops are brittle. When a downstream tool updates its API schema, when a regulatory form changes, when an edge case slips through — the agent silently returns wrong answers, or fails outright. Enterprises end up with a growing roster of “broken agents” tickets and the engineering team caught in a maintenance treadmill instead of building new capability.
1.2 Runaway Token Cost
Every agent invocation re-reasons the workflow from scratch. The tax-filing agent thinks through the same logic ten thousand times per month. The compliance agent re-derives the same checks. There is no caching of successful reasoning trajectories — only the much weaker prompt-level cache. Token spend therefore scales linearly with usage and never compresses.
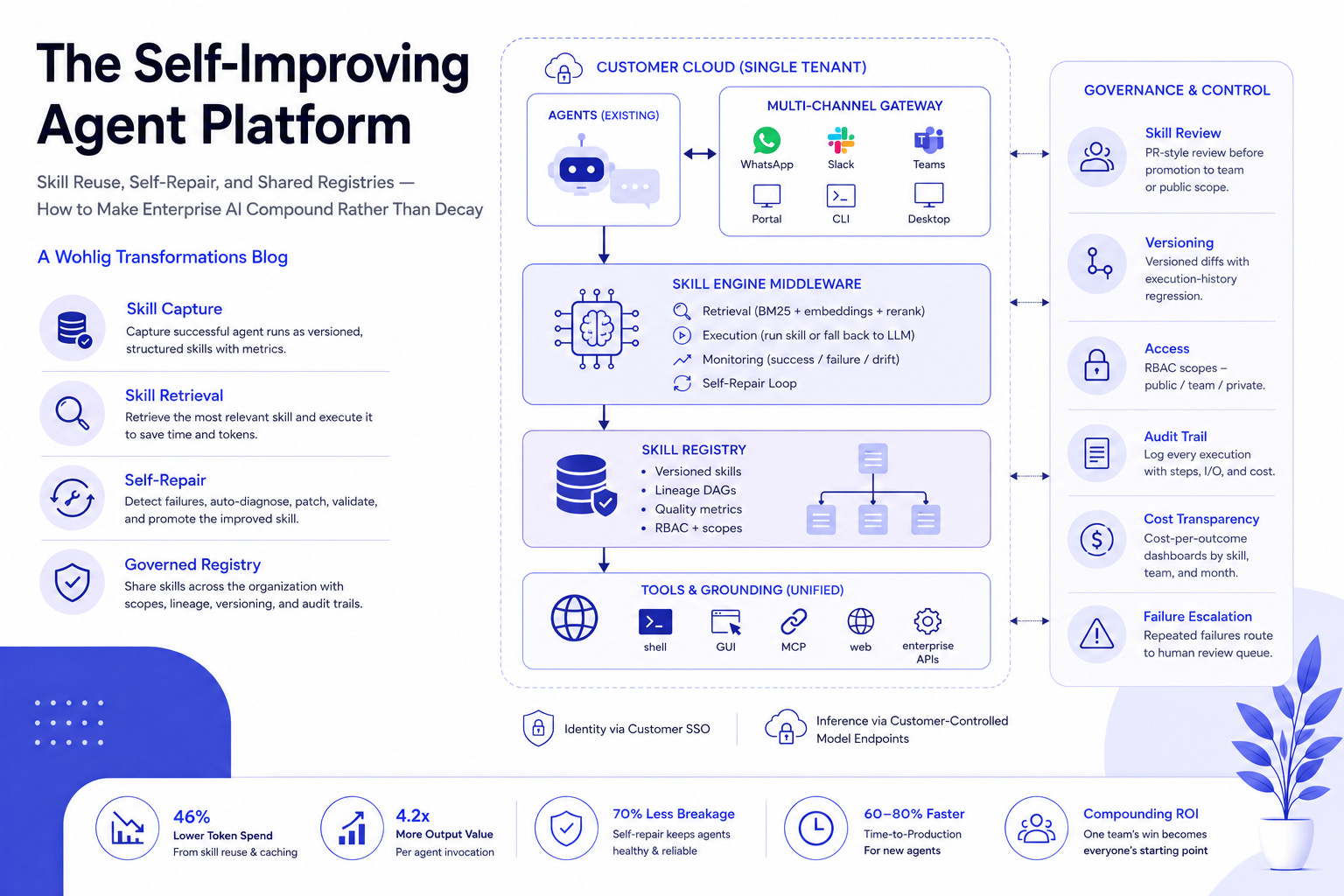
2. Solution Pattern
A middleware layer between agents and tools, with three capabilities:
2.1 Skill Capture
A successful agent run is captured as a named, versioned, structured skill — input schema, tool calls, decision points, output schema, quality metrics. Stored in a registry.
2.2 Skill Retrieval
On a new task, the platform retrieves the most relevant existing skill (hybrid retrieval — lexical, semantic, and LLM-rerank). If a skill matches, the agent executes the skill rather than reasoning from scratch. Token cost drops dramatically.
2.3 Self-Repair
Skill executions are monitored continuously. When a skill fails — schema drift, edge case, tool change — the platform diagnoses the failure, generates a patched version of the skill, validates it against historical executions, and promotes it to the registry. The agent is healed without human intervention.
2.4 Governed Registry
Skills are stored in a registry with public / team / private scopes, lineage DAGs (which skill descended from which), diff-based change tracking, and audit trail. Skills are discoverable across the organization — one team’s win becomes the next team’s starting point.
3. Architecture
┌─────────────────────────────────────────────────────┐
│ Customer Cloud (single tenant) │
│ │
│ ┌─────────────┐ ┌─────────────────────────────┐ │
│ │ Agents │ │ Multi-Channel Gateway │ │
│ │ (existing) │ ◀▶│ WhatsApp · Slack · Teams │ │
│ └──────┬──────┘ │ Portal · CLI · Desktop │ │
│ │ └─────────────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────────────────────┐ │
│ │ Skill Engine Middleware │ │
│ │ · Retrieval (BM25 + embeddings + rerank) │ │
│ │ · Execution (run skill or fall back to LLM) │ │
│ │ · Monitoring (success / failure / drift) │ │
│ │ · Self-Repair Loop │ │
│ └─────────────┬──────────────────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────────────────────┐ │
│ │ Skill Registry │ │
│ │ · Versioned skills │ │
│ │ · Lineage DAGs │ │
│ │ · Quality metrics │ │
│ │ · RBAC + scopes │ │
│ └─────────────┬──────────────────────────────────┘ │
│ ▼ │
│ ┌────────────────────────────────────────────────┐ │
│ │ Tools & Grounding (unified) │ │
│ │ shell · GUI · MCP · web · enterprise APIs │ │
│ └────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
Deployed inside the customer’s tenancy. Identity through the customer’s SSO. Inference can route to a customer-controlled model endpoint for sensitive workloads.
4. Governance Model
The platform makes AI governance auditable in a way ad-hoc agents cannot:
Skill review — All new skills go through PR-style review before promotion to “team” or “public” scope.
Versioning — Every skill change is a versioned diff with execution-history regression.
Access — RBAC scopes — public / team / private — enforced at the registry.
Audit trail — Every skill execution logged with inputs, outputs, intermediate steps, and cost.
Cost transparency — Per-skill, per-team, per-month cost-per-outcome dashboards.
Failure escalation — Skills that fail repeatedly route to a human review queue rather than auto-patching indefinitely.
5. Outcomes
Token cost reduction — 30–50% (compounds with adoption)
Agent reliability uplift — substantial — silent decay replaced by self-repair
Capability reuse across teams — order-of-magnitude (one skill, many consumers)
Time-to-deploy a new agent capability — from weeks to days
ROI auditability — yes (per-skill cost & outcome metrics)
6. Where It Fits
Enterprises running 5+ AI agents in production with rising token bills.
BFSI back-office — KYC, document processing, regulatory filings, dispute handling.
Professional services — tax, audit, legal, compliance — with high-volume repetitive knowledge work.
BPO and KPO operations wanting to industrialize AI-assisted delivery.
Engineering and manufacturing with recurring spec, compliance, and documentation generation.
Product companies building agent platforms who need a governed skills layer without building it from scratch.
7. Engagement Model
Phase A — Discovery (2 weeks). Inventory existing agents and their failure modes. Map current token spend and reliability metrics. Identify the highest-leverage candidates for skill extraction.
Phase B — Platform deploy (4–6 weeks). Stand up the skill engine, registry, and dashboard inside the customer’s cloud. Wire to existing agent runtimes via the standard protocol layer.
Phase C — Skill migration (8–12 weeks). Wrap existing agents as skills. Establish the review workflow. Onboard 3–5 teams. Begin measuring savings and reliability.
Phase D — Operate (ongoing). Wohlig stays as managed service, hybrid, or advisor.
8. About Wohlig
Wohlig Transformations is a digital transformation, cloud, and AI consulting firm founded in 2016. We have shipped 10+ generative-AI solutions in production, completed 20+ cloud migrations, and hold 40+ Google Cloud certifications. We serve governments (Maharashtra, Gujarat, ONDC), enterprises (Lodha, Eros Now, Hungama), and high-growth consumer companies (Swiggy, Ninjacart, PW Live).
Offices: India and London. Web: www.wohlig.com.
To discuss your enterprise AI scaling, reach Wohlig at chintan@wohlig.com.